
DDGI是一个核心基于硬件光追的"体素化"的实时GI方案(主要对Diffuse Illumination),同时也是RTXGI的核心技术。这里我们基于DDGI的论文与演讲文档[1]与[2]实现了DDGI的主要流程,当然,在完成了我们自己的DDGI主要流程后,也参考了[3]进行了改进与优化。
为什么选择DDGI?
- 与[2]最后所设想的Stream GI一样,唯有"体素化"的(“网格化"的)方案才能更好的接入未来基于服务器的辅助渲染技术。
- 动态的、“体素化"的,这很适合箱庭+即时(或实时)PCG的游戏的高品质GI方案。
NOTE
项目地址: RicciFloOow/Unity-DDGI: Global Illumination Based On DDGI In Unity
DDGI流程
我们先来看未优化前我们与官方的DDGI的流程的异同
NOTE

可以看到,我们处理Probes的状态的方法以及对高阶反弹的处理与官方版的有很大的区别。项目里我们基于官方版的修改了高阶反弹的方案,不过,这也导致了一些其它问题。
官方的DDGI
作为实打实踩过坑的人,如果有人看到了这篇文档,还是希望能先下载官方的DDGI看看他们的实际流程,少走点弯路。不过需要注意的是,官方的DDGI项目的部署也有坑。
- 官方的DDGI就是[3]NVIDIAGameWorks/RTXGI-DDGI: RTX Global Illumination (RTXGI),其中的QuickStart给出的git的地址是错误的:指向的是完整的RTXGI的项目(文档中给的是
https://github.com/NVIDIAGameWorks/RTXGI.git但实际是https://github.com/NVIDIAGameWorks/RTXGI-DDGI.git)。 - 另一个问题就是克隆下来的项目可能是不完整的,我试了几次,都是
RTXGI-DDGI\external\agilitysdk中缺失几乎整个sdk(好像只有个version文件),需要自行下载Agility SDK并拷贝至该文件夹下。
其余的只需要按照QuickStart中的步骤做就行了。
Probe状态机
我们先来看Probe的状态逻辑。DDGI相对于传统的光照探针方案的一大优点就在于DDGI可以利用光追的结果"自动化"的“优化”自身的位置并判断自身是否处于物体"内部"从而无效。那么该如何判断是否处于物体内部?一个自然的想法便是基于射线命中时是命中的正面还是反面来判断。
官方的SDK里的提供的方案和我们上面说的大致类似,也是基于正反面,然后基于距离(反面的取负值)计算权重估计是否需要活跃。
但是这样做其实是存在问题的,比如在绝大多数情况下网格间的重合是不可避免的,这可能会导致一个探针有更多的射线先碰到重合的网格的正面,从而导致对当前Probe状态的误判。而且DDGI是一个允许离线烘焙的技术,在仅基于正反面的基础上来判断探针是否处于"墙内”,在我看来是远远不够的。我们的思路是利用场景中"绝对"不会在"墙内"的对象来辅助判断:比如游戏中的玩家相机位置,一些点光源的位置,这些对象从游戏设计上就不会处于"墙内”。
因此,
- 我们的第一步是Probe均匀向外发射射线,然后在命中点处发射指向前面提到的用于辅助判断的对象的位置的射线(注意,不需要全部,只需要几个有特征,比较重要的即可),如果Miss了,那么向Directional Light的方向发射足够长的射线看看是否碰撞。之后统计是否有足够的无碰撞的射线来判断Probe是否有效。
- 仅靠一次反弹通常是不够的,所以我们后面的步骤就是将Probe的活跃信息向周围"扩散":一个活跃的Probe均匀向外发射射线,在命中点处发射指向另一个Probe的射线,然后统计是否有足够的无碰撞的二次反射射线。重复以上操作将活跃信息"扩散"至全部网格。
不过需要注意的是,上述的"扩散"过程其实和计算SDF是相似的,因此我们参考了JFA加速的方案,逐步增加扩散的步长(当然,会有一定的上限,过大了可能通常是无效的),而不是仅靠"扩散"至相邻Probe来实现。不过这个过程还是与SDF有一定的区别,因此存在极端情况使得扩散的结果并不好,比如下图这种左下角有个光源,探针在右下角的情况(蓝色区域是墙)。
此外需要注意的是,这种检测需要发射的射线还是不少的,由于Unity 2022.3.+版本还不支持用ArgBuffer来分配RTS的线程组(当然,DXR是支持的),因此需要手动分配到多帧来执行(手动分步模拟异步,RTS是同步的)。如果不手动分配到多帧执行,只要Probes Grid一大,就会可能导致单帧渲染超时,从而系统强杀进程使得应用闪退,这一点可以用项目中的Assets/DynamicDiffuseGI/Demo/DemoScene/DemoProbe2FlattenOct.unity场景来测试。
尽管RTS中是没法同步组的(group shared memory只支持CS),理论上我们还是可以利用Warp来加速的(对Probe的有效射线的统计)——只要线程组分配合理
| |
不难发现这种方案的准确性会更高,但是代价是开销会更大,因此如果场景发生了改变,理论上应该只重新检测场景变化的部分的包围盒所影响的Probes。
当然,官方除了处理了"墙内"的Probe的状态以外,也对那些Probe所"影响的范围内"没有任何物体的Probe进行了处理——不活跃的(没必要浪费性能),像下图中红色描边的探针就是官方的Cornell盒场景中不活跃的。我们在后面的改进版中也基于此想法修改了这类Probes的状态。

高阶反弹
[4]提到DDGI的辐照度约为光线二次及以后的高阶(多次)反弹的漫反射项的总和,因此我们记录的irradiance就应该基于此来计算。在本项目里,我们实现了两种高阶反弹的方案,第一种是在Probe网格内基于8-邻域或是26-邻域(我们用26-邻域)采样并传递,第二种则是DDGI官方的那种,在Probe Tracing的同时就采样命中点的邻近Probes来实现传递。我们项目里的Demo场景DemoProbe2FlattenOct用的还是第一种方案,DemoCornellBox场景则在后面的优化中改用了方案二。
方案一相对于方案二的唯一的优点就只有可以更清晰的看到多次反弹的分解过程

而且方案一在网格间传递的过程中是没法获得albedo的,只能用之前的irradiance来模拟,这实际上会使得误差更大。而方案二则确实是光线二次及以后的高阶反弹的漫反射项的和。
Probe Tracing
我们的Probe Tracing与官方的最大不同点在于我们的depth与irradiance的Tracing是分离的。那么为什么(一定)要分离呢?
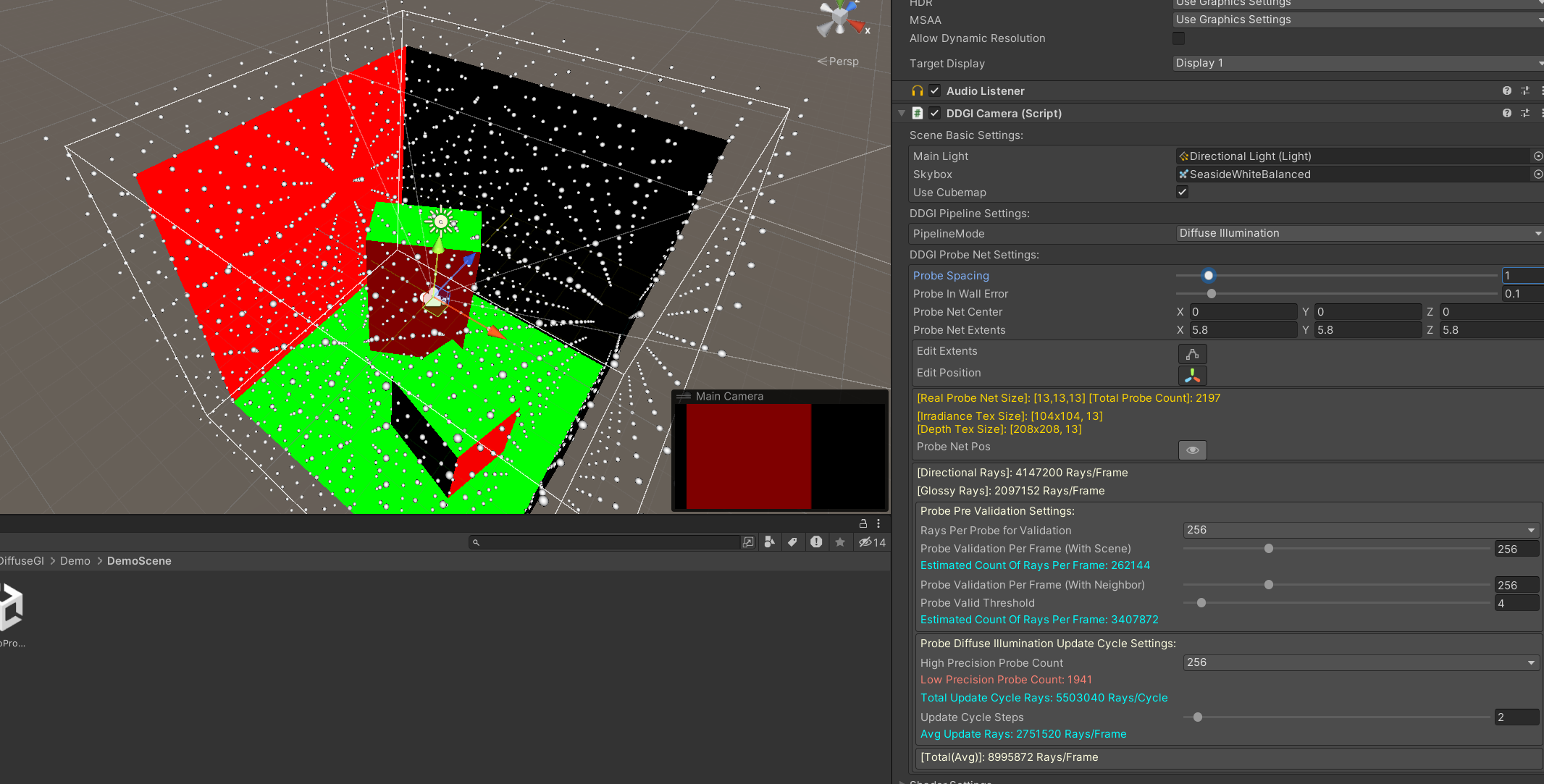
首先我们的Probe在Tracing时的精度是不同,我们期望在相机附近的Probes在Tracing时,单个纹素使用的射线数量更多(可以看下文我们关于射线分布的设计),这样我们的结果会相对来说更快的收敛且精确(高精度的16rpp,低精度的4rpp)。但是这样会造成一个问题,就是depth通常要比irradiance用的纹理大,如果为了满足depth的精度,那么irradiance会有很多相对来说"浪费"的(“重复"的)Tracing了。而且depth严格来说只需发射一个射线,而irradiance则需要发射两个射线,且还需要额外的Buffer或是纹理的采样(法线肯定得采样的)。因此,我们将这两种分开来Tracing了。
Glossy Illumination
至于Glossy Illumination,我们是按照[2]中的方案来实现的,用bilateral blur downsample来得到mipmap的
| |
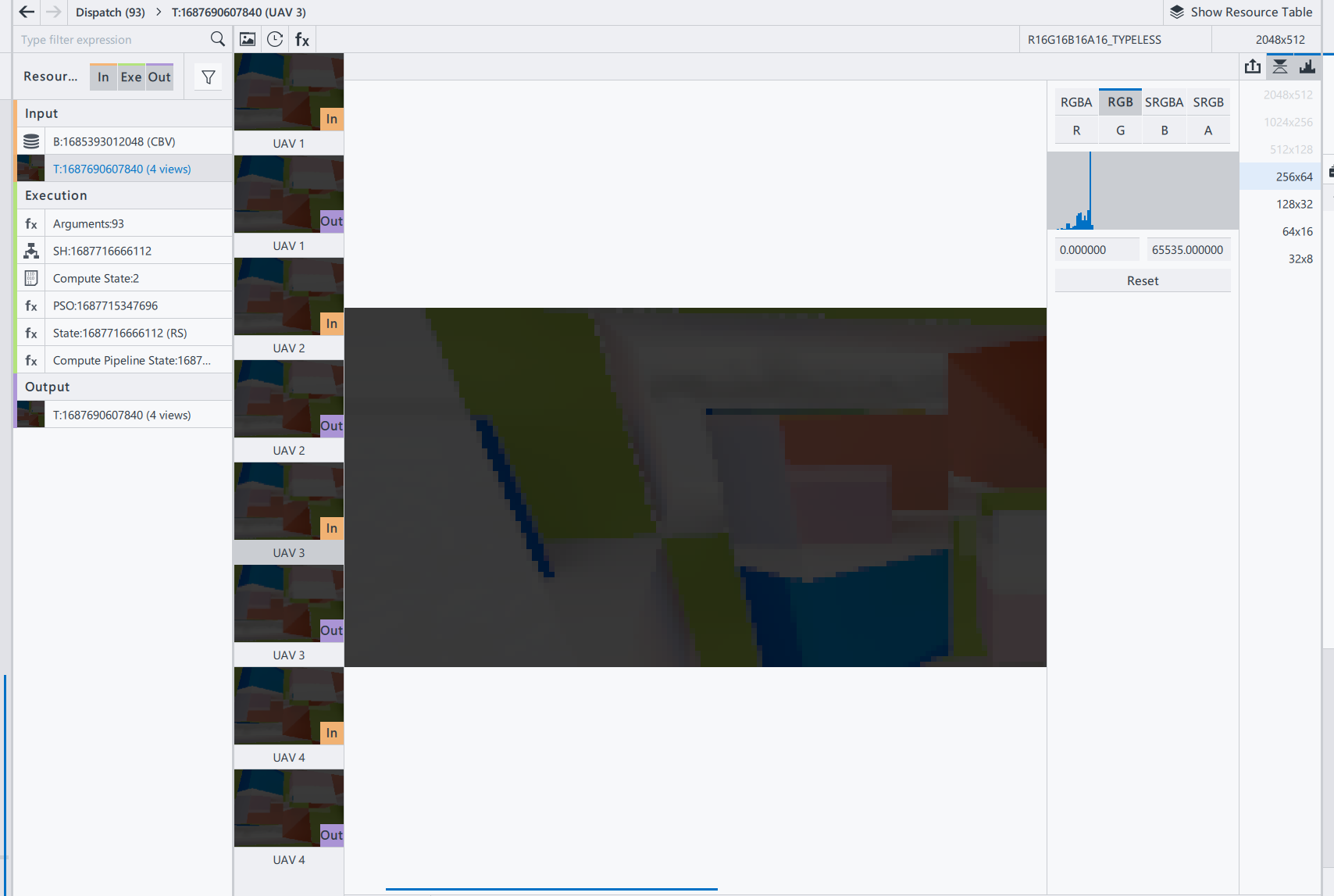
可以看到细节还是有所保留的。
NOTE
射线与分布
以下是我们的渲染结果



不难发现我们的结果有明显的网格感,这是因为我们的Probes的分步是网格分布——太均匀了(场景也过于简单),如果基于场景自行Relocate效果会好一些(实际上,如果将官方的示例中的Cornell盒的天空盒改成白色的,也能看到一定的网格感)。但是如果Relocate了,那么又可能会导致Chebyshev计算的权重的"异常"加剧,像官方示例中的Cornell盒就有明显的异常分界带

射线的方向
射线方向也算是一个有点小坑的地方。DDGI推荐使用Spherical Fibonacci Grids计算射线方向,并用[5]中的八面体展开映射$\varphi:\text{dir}\mapsto\text{coord}$来储存Probes发出的射线的结果(irradiance和depth)。很显然,对一个$n\times n$的纹理,如果我们仅生成$n\times n$条射线$(n>2)$,是一定存在像素不是任何生成的射线方向在$\varphi$下的像——即$\varphi$不是满射的情况的。自然的,对于$n\times n$的纹理,我们是否可以通过生成$m\times m$条射线$(m>n)$使得基于任意的初始方向生成的这些射线方向在$\varphi$下是满的呢?数学上应该可以算出这样的$m$的下界,不过我们这里没必要去计算,因为即便$m=n+2$,仍然可能不是满的。总的来说,就是我们需要生成更多的射线才可能覆盖满我们目标存储的纹理。
我们在场景Assets/DynamicDiffuseGI/Demo/DemoScene/DemoProbe2FlattenOct.unity中采用的方案就是最直接的利用尽可能多的射线来覆盖目标纹理的方法:
| |
但显然,上面这种方案的性能是极差的。因此一种自然的改进方案就是利用一个中间的纹理(当然实际是多个)来记录单个射线的结果,然后再在CS中来将结果映射到我们实际临时纹理中(一般用group shared memory,不过这限制了目标纹理的分辨率),之后再输出到指定的Texture2DArray中。这个其实就是官方所使用的方案。
那么有没有办法可以不用中间纹理?自然是有的,只需要我们保证我们分配的方向能保证覆盖全部纹素,并且每个纹素能对应我们期望数量的射线方向,那么我们就可以直接基于纹素坐标去获取射线方向,从而省去了中间纹理这一步骤。这个射线方向分配方案就存在一个坑。
对$n\times n$的纹理,我们期望每个纹素都有$k$条射线。于是我最初的方案是,我们生成$m\times m$条射线,然后利用$\varphi$将射线对应的纹素坐标计算出来,把这个射线添加到该纹素对应的一个容器里,等全部映射完了再检查一下容器里的射线是否足够k条,如果不够则通过插值或是其他的随机方案来生成足够的射线。不过,这个方案在实际项目中是完全不能用的。我花了不少时间才定位到Chebyshev权重异常的原因,就是这个射线分配方案:即使在混合了非常多的帧的结果后,一些在理应呈现出对称的结果的地方仍然是明显非对称的。
优化后的是SphericalFibonacciRay.cs中所使用的方案:我们之前的方案给出的条件太苛刻了,因为八面体展开映射下的纹素之间在球面上的投影差异本身就不小,如果我们非常严格的基于纹素对应的方向来生成不足的射线,得到的结果将总是很不均匀的。因此我们考虑将射线同时记录进其所属的纹素的$3\times3$邻域内。并且即便当前纹素内的射线不够,我们也不再生成别的射线了,而是重复使用容器内的射线。不过这个方案在cpu端实现起来开销巨大(我本来还打算考虑使用射线与纹素方向的内积值为权重来排序),因此最终我们还是实现了一个GPU版的(见RandomRayGenerator.compute)。
射线长度
射线越短,通常来说开销越小。我们先来看一下官方的Demo中的深度图的数据
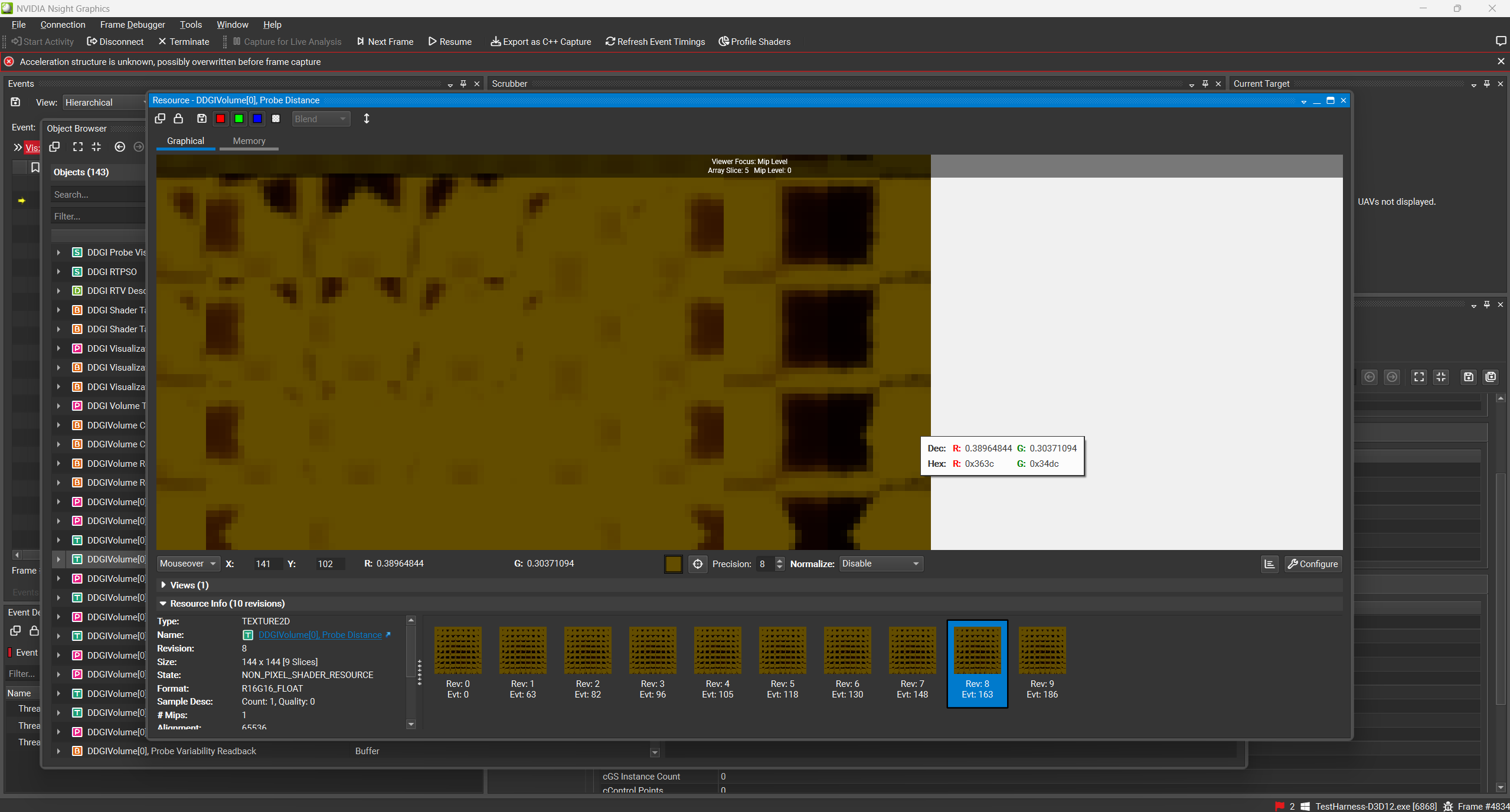
可以看到里面存的距离居然不到0.4,这其中一个原因是这个Demo中的Cornell Box本身就比较小,另一个就是他们在写入深度的时候限制了距离:基于Probe的间距(官方是取了1.5倍)。我们在项目了直接令射线长度是Probe的间距的1.733倍,这是因为我们的depth与irradiance的检测是分离的。不过这也就要求了我们必须对全部Miss的Probe的状态做处理。
总结
说实话,做DDGI之前我对其还是抱有很大期望的,但是实际做出来后(包括官方的Cornell Box的Demo),还是有那么些失望的——没有达到我的预期。更重要的是,本来我期望DDGI能对高频变化的场景能有很好的响应(当然,官方本身的逻辑下是无法做到很及时的响应的),不过这一点实测还是无法实现的。
References
[1]Dynamic Diffuse Global Illumination with Ray-Traced Irradiance Fields
[2]DDGI with Ray-Traced Irradiance Fields Presentation
[3]NVIDIAGameWorks/RTXGI-DDGI: RTX Global Illumination (RTXGI)
[4]Dynamic Diffuse Global Illumination Resampling
[5]Survey of Efficient Representations for Independent Unit Vectors (JCGT)