注意,本文也存在未能找出原因的反常结果。
用多少顶点来绘制一个三角形效率最高
我们知道一个三角形就三个顶点,而且我们也知道一个网格的顶点数量越少其渲染所需时间越少。那么对于一个三角形来说,用三个顶点来绘制,效率就一定最高吗?
初步分析
如果对软光栅化有基本的了解,那么应该知道,一个三角形在光栅化之前,需要基于其NDC空间的坐标确定一个AABB。然后我们再对这个AABB所包含的全部像素进行逐像素遍历,并基于Top-Left规则判断像素是否属于三角形内部(我们默认考虑的是标准光栅化,这里不考虑保守光栅化)。
那么很自然的,对任意的一个如下图所示的三角形$\triangle ABC$,

我们可以用一条水平线段$DC$将三角形分为两个$\triangle ADC$与$\triangle DBC$,

很显然,这两个分割后的三角形的包围盒要比原始的三角形的包围盒小不少(可以剩下不少需要遍历的像素)。那么渲染这样分割后的三角形是否会比一整个的三角形更快呢?当然,我们也需要考虑到光栅化之前的顶点操作:只要post-transform cache起作用了(像这里我们绘制时提供索引的buffer),那么在顶点提交环节实际上也就多计算了一个顶点而已。
于是,我们考虑绘制1000个如下三角形到一个8192x8192的纹理中(用Size=5的正交相机,并用PCG Hash实现固定的伪随机位置),
| |
考虑到用Profiler工具抓取单帧的结果误差会很大,所以我们就直接用unity的CustomSampler来采集绘制开销。在AMD RX6600下,我们采集了100000帧的绘制开销(运行30秒后再采集,保证GPU处于预热状态),结果如下,

可以看到用分割后的三角形渲染比用完整的三角形渲染,确实能更快一些。
光栅化流程的加速
我们上面测试的三角形在分割后,其包围盒面积是完整的$75%$,如果硬件光栅化的过程完全与我们最开提到的软光栅化的流程一样,我们这种“优化”应该能有很显著的性能提升才对。但是实际上提升的并不明显(可能开销就减少了10us左右)。
原因在于,硬件光栅化的过程比我们上面说的软光栅化的过程要复杂多了(实际上工业级的软光栅化也是如此)。比如[1]Laine,Samuli,et al (2011)中设计的软光栅化管线
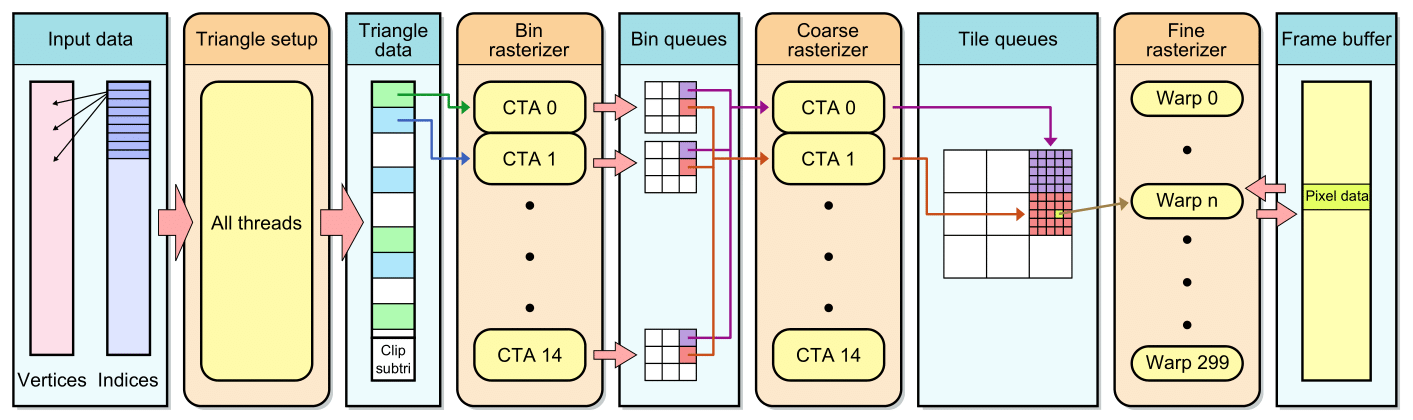
就是由多个用于分配的"层级"组成的。因此,以上图所示的管线为例,我们实际做的不过是减少了Bin Rasterizer与Coarse Rasterizer的少量工作,自然没有特别大的性能提升。事实上,上面的软光栅化管线即使面对当年的硬件光栅化管线,也有不少的差距,更别说现在的硬件了。
我们用同样的方式在Nvidia的RTX4070下测试可得

可以看到完整三角形的绘制比分割后的三角形开销要少太多了,这表明N卡硬件光栅化的低、中层级的分配与剔除阶段的性能极为优秀。不过,为什么分割后的渲染开销居然是完整的2倍还不止,甚至(似乎)比RX6600的还差?当然,unity的CustomSampler得到的可能并不是完整的绘制开销,因此我们用Nsight分别抓帧来对比一下(从unity中采集的结果来看,N卡的渲染开销还是比较稳定的,所以我们抓的单帧还是有一定参考性的)。
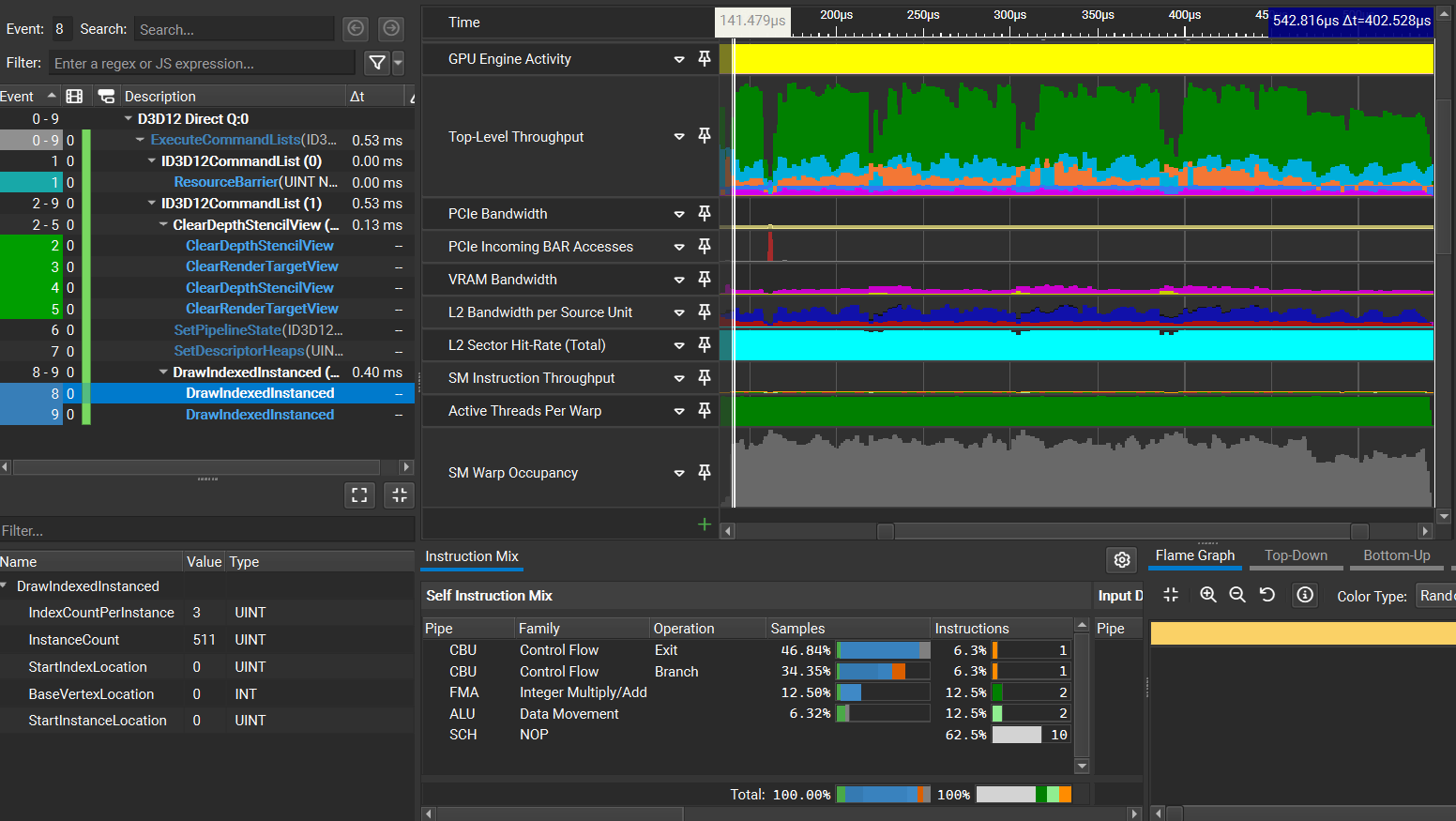
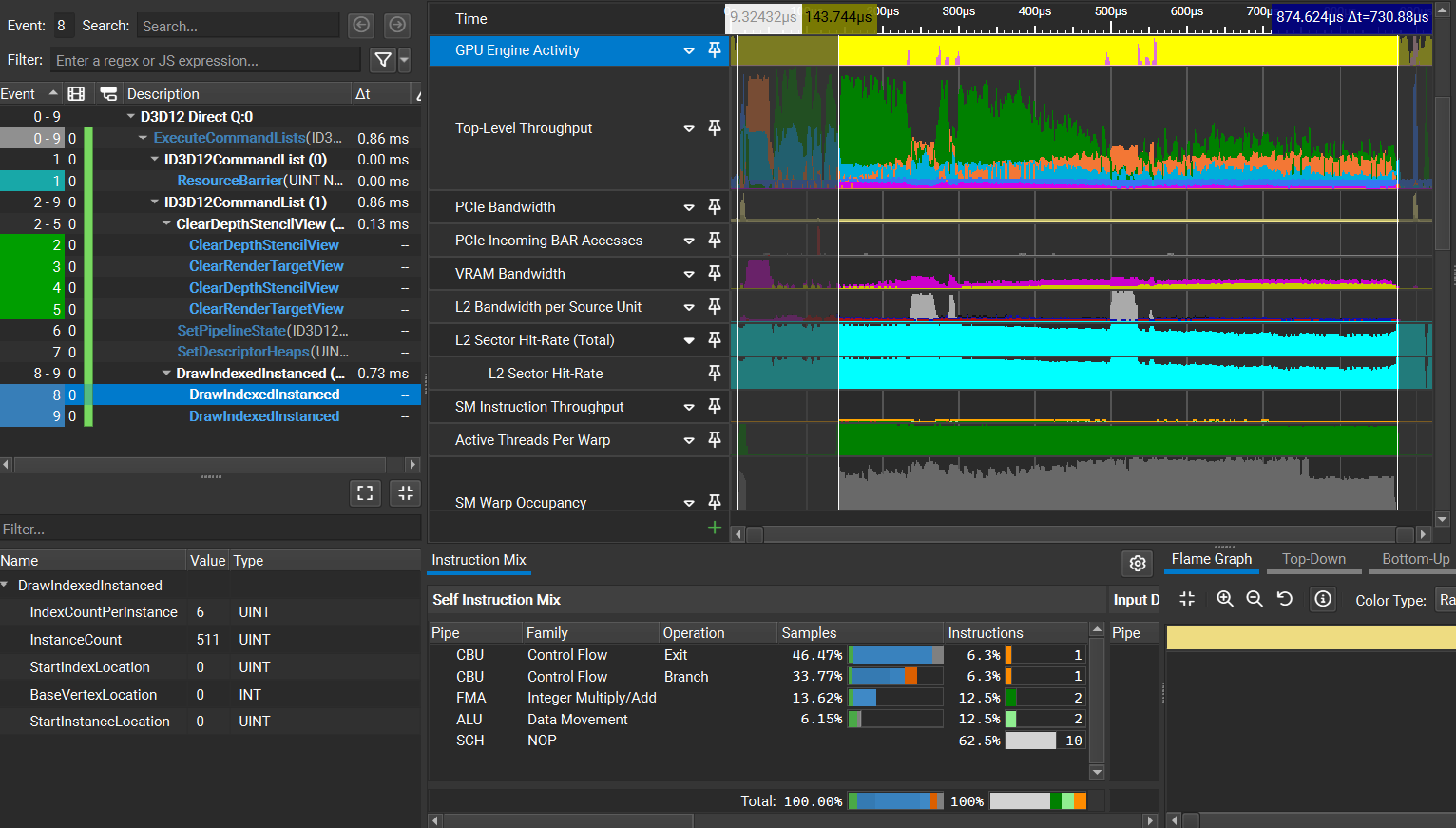
我们可以看到分离后渲染的Warp利用率波动很大,且存在利用率很低的情况。我们用Nsight的Trace Analysis View来查看可能的原因,
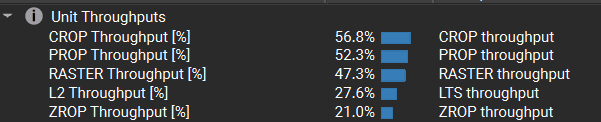

可以看到分割的三角形的光栅化相关的吞吐量都小于完整的三角形的,但VRAM吞吐量却相对较高。注意到分离的三角形的Timeline中,VRAM与L2带宽存在两个(更准确点是四个)明显的峰值,因此有可能是因为我们渲染目标的尺寸太大了(8192x8192),导致ROP单元在输出颜色与深度时出现瓶颈。仔细一想,我在配置这些三角形的时候是由近及远的,那么如果反着分配一下呢(由远及近)?
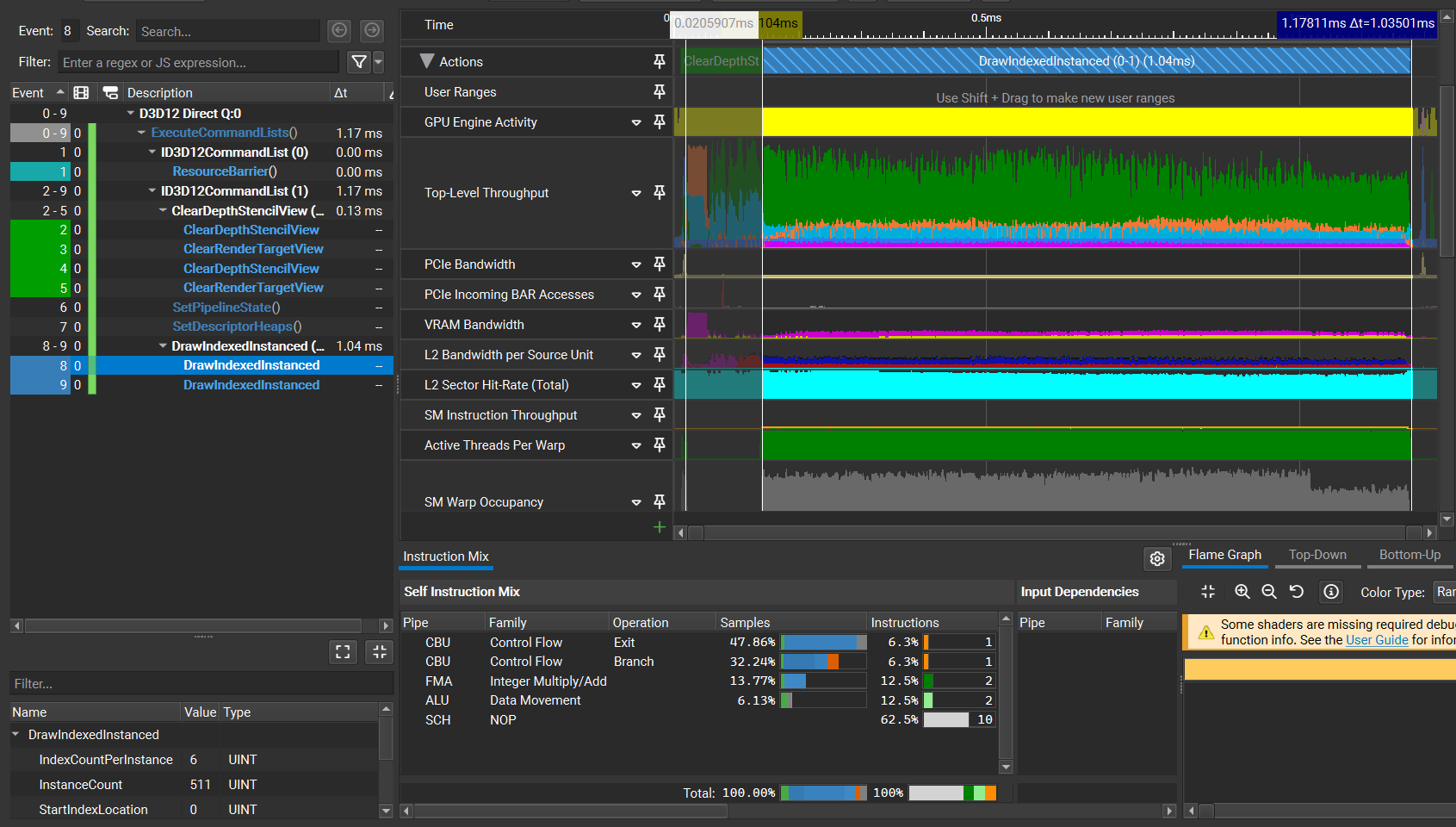
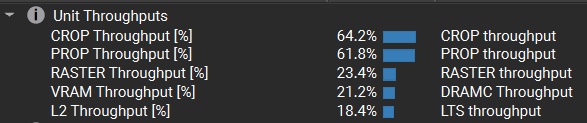
可以看到,尽管吞吐量和利用率有所提升,但由远及近的渲染排序导致 overdraw 过于严重,进而大幅增加了开销(光栅化的吞吐量更低了)。但是这里就又引出了一个奇怪的点,为什么这时候并未出现带宽上的瓶颈期呢?这一点暂时猜测为:因分离的三角形的重合边的early z效率低下导致的。
References
[1]High-Performance Software Rasterization on GPUs
光栅化的硬件深度与PS中的硬件深度
VFX中我们经常会有在PS中用NDC坐标获得屏幕坐标或是深度的需求,那么一个很自然的问题就产生了:PS中计算得到的深度,如果在PS中输出至SV_Depth,会和直接通过硬件光栅化流程输出至Z-Buffer的效果完全等效吗?
要验证上面这一点,我们只需两个Pass:
- 第一个Pass:我们利用NDC坐标向
SV_Depth写入PS中的硬件深度
| |
- 第二个Pass:则利用
ZTest Equal来对比深度即可
| |
如果深度相等,那么对指定的网格,其渲染得到的结果应该是全白的。但事实并非如此,

如果我们把渲染目标的尺寸设为32x32的,然后从GPU中回读这两个深度的位模式(以下我们取一段片段)
- 00000000
- 00000000
- 00000000
- 3E250C66
- 3E233F3F
- 3E217219
- 3E1FA4F2
- 3E1DD7CC
- 3E1C0AA5
- 3E1A3D7F
- 3E187059
- 3E16A332
- 3E14D60C
- 3E1308E5
- 3E113BBF
- 3E0F6E98
- 00000000
- 00000000
- 00000000
- 00000000
- 00000000
- 00000000
- 3E250C66
- 3E233F40
- 3E21721A
- 3E1FA4F2
- 3E1DD7CB
- 3E1C0AA6
- 3E1A3D7F
- 3E187059
- 3E16A333
- 3E14D60D
- 3E1308E6
- 3E113BC0
- 3E0F6E99
- 00000000
- 00000000
- 00000000
可以看到确实有深度存在非常微小的差异:相差个0x00000001。我没法保证这样的误差完全是由以下原因造成的,不过应该是造成这种误差的主要来源。我们设$v_a, v_b$是顶点$a$与$b$的NDC坐标,那么对线段$ab$中的一点$c$,其硬件深度应该由顶点$a$与$b$的深度插值得到,即
而在PS中,需要经过插值(默认的)再进行透视除法,即
$$ d_{PS}=\frac{lerp(v_a,v_b,t).z}{lerp(v_a,v_b,t).w}, $$数学上来说这两个公式是一样的,但是浮点数因其精度问题,确实会因此产生极小的误差。
三角形的定向与索引顺序
我们知道,三角形的索引顺序决定了一个三角形的"正面",那么一个自然的想法就是:如果一个三角形只绘制背面,然后我们在GS中手动调整顺序,使其"反向"(也就是将$1,2,3$改为$1,3,2$),那么这样获得的三角形与正常只绘制正面的三角形应该是一样的。于是我们就按照这样的思路实现两个Pass,分别输出到不同的深度图里,
| |
然后我们再用一个Pass来比较深度:如果是"天空盒"则返回黑色,如果是相同的则返回蓝色,否则,返回白色。在N卡中,我们用于渲染的网格的区域总是蓝色的,也就是说我们的假设是成立的。但是在AMD RX6600下,事情就变得有趣起来了
这难不成是渲染界的宇称不守恒?